e-Banking Fraud Detection using Data Mining
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 4638 words | ✅ Published: 18 May 2020 |
1. Introduction
1.1. Define e-fraud
e-fraud can be briefly defined as Electronic Banking scam and deceit which affects the whole society, impacting upon people, organization and even governments.
Because of the risk inherent in the e-channel space, many organizations have attempted to implement the following comprehensive strategies for detecting and preventing e-fraud:
- Fraud Prevention Strategies
- Fraud Risk Analysis
- Fraud Awareness
- User Training
- Monitoring
- Collaboration with Police and other organizations
1.2. Statement of problem
E-banking is a driving force that is changing the scenery of the banking environment primarily towards a more competitive and advanced industry with keeping customer’s convenience in mind. Electronic banking has bridged the gap between multiple financial institutions, which enabled new financial products and services, and made existing financial services available in different options. The developments in electronic banking together with other financial innovations are constantly bringing new challenges.
The following inherent factors are generally a cause of e-fraud:
- Increased use of e-payment systems for transactions due to its simplicity;
- Emerging e-payment methods adopted by banks;
- Complexity of e-channel systems setup
- Abundance of malicious code, malware and tools available to hackers
- Continues innovations in this area;
- Poor security practices and knowledge gap
- Insignificance approach of the internet
- Third-party processors in switching e-payment transactions;
- Passive approach to fraud detection and prevention
- Lack of inter industry collaboration in fraud prevention
1.3. Major Techniques to commit e-fraud?
Hackers uses various techniques to commit e-fraud, including but not limited to:
- Cross Channel Fraud: customer information obtained from one channel (i.e. call center) and being used to carry out fraud in another channel (i.e. ATM).
- Data theft: hackers access secure or non-secure sites, get the data and sell it.
- Email Spoofing: changing the header information in an email message in order to hide identity and make the email appear to have originated from a trusted authority.
- Phishing: refers to stealing of valuable information such as card information, user IDs, PAN and passwords using email spoofing technique.
- Smishing: attackers use text messages to defraud users. Often, the text message will contain a phone number to call.
- Vishing: fraudsters use phone calls to solicit personal information from their victim.
- Shoulder Surfing: refers to using direct observation techniques, such as looking over someone’s shoulder, to get personal information such as PIN, password, etc.
- Underground websites: Fraudsters purchase personal information such as PIN, PAN, etc. from underground websites.
- Social Media Hacking: obtaining personal information such as date of birth, telephone number, address, etc. from social media sites for fraudulent purposes.
- Key logger Software: use of malicious software to steal sensitive information such as password, card information, etc.
- Web Application Vulnerability: attackers gain unauthorized access to critical systems by exploiting weaknesses on web applications.
- Sniffing: viewing and intercepting sensitive information as it passes through a network.
- Google Hacking: using Google techniques to obtain sensitive information about a potential victim with the aim of using such information to defraud the victim.
- Session Hijacking: unauthorized control of communication session in order to steal data or compromise the system in some manner.
1.4. Objective of this paper
The main objective of this study is to find out the solution of controlling E-banking and Credit card fraud, since it seems to be a critical problem in many organizations including the government. Specifically, the following are objective of the study;
- Identify the factors that cause fraud,
- Explore the various data mining techniques of fraud detection
- Explore some major detection techniques based on the unlabeled data available for analysis, which do not contain a useful indicator of fraud. Thus, unsupervised Machine Learning and predictive modeling with major focus on Anomaly/Outlier Detection (OD) will be considered as the major techniques for this project work.
Using sophisticated data mining tools, millions of transactions can be searched and spot for patterns and detect fraudulent transactions. Using sophisticated data mining tools such as Decision trees: Booting trees, Classification trees and Random forest; Machine learning, Association rules, Cluster analysis and Neural networks. Predictive models can be generated to estimate things such as probability of fraudulent behavior or the naira amount of fraud. These predictive models help to focus resources in the most efficient manner to prevent or recover fraud losses.
2. Credit card and e-banking fraud detection
Credit card fraud is divided into two types: offline fraud and Electronic fraud. Offline fraud is committed by using a stolen physical card at a storefront or call center. In most cases, the institution issuing the card can lock it before it is used in a fraudulent manner, if the theft is discovered quickly enough. Electronic fraud is committed via web, phone shopping or cardholder-not-present. Only the card’s details are needed, and a manual signature and card imprint are not required at the time of purchase. With the increase of e-commence, Electronic credit card transaction fraud is increasing. Compared to Electronic banking fraud detection, there are many available research discussions and solutions about credit card fraud detection.
Most of the work on preventing and detecting credit card fraud has been carried out with neural networks. CARDWATCH features a neural network trained with the past data of a particular customer and causes the network to process current spending patterns to detect possible anomalies. Brause and Langsdorf proposed a rule-based association system combined with the neuro-adaptive approach. Falcon, developed by HNC, uses feed-forward Artificial Neural Networks trained on a variant of a back-propagation training algorithm. Machine learning, adaptive pattern recognition, neural networks, and statistical modeling are employed to develop Falcon predictive models to provide a measure of certainty about whether a particular transaction is fraudulent. A neural MLP-based classifier is another example of a system that uses neural networks. It acts only on the information of the operation itself and of its immediate previous history, but not on historic databases of past cardholder activities.
A parallel Granular Neural Network (GNN) method uses a fuzzy neural network and rule-based approach. The neural system is trained in parallel using training data sets, and the trained parallel fuzzy neural network then discovers fuzzy rules for future prediction. Cyber Source introduces a hybrid model, combining an expert system with a neural network to increase its statistic modeling and reduce the number of “false” rejections. There are also some unsupervised methods, such HMM and cluster, targeting unlabeled data sets.
All credit card fraud detection methods seek to discover spending patterns based on the historical data of a particular customer’s past activities. It is not suitable for Electronic banking because of the diversity of Electronic banking customers’ activities and the limited historical data available for a single customer.
2.1. Credit Card Fraud Detection Data Mining Methods
On doing the research for this paper, I come to the conclusion that to detect e-fraud there are a lot of approaches, stated as follows:
- A Hybrid Approach and Bayesian Theory.
- Hybridization
- Hidden Markov Model.
- Genetic Algorithm
- Neural Network
- Bayesian Network
- K- nearest neighbor algorithm
- Stream Outlier Detection based on Reverse K-Nearest Neighbors (SODRNN)
- Fuzzy Logic Based System
- Decision Tree
- Fuzzy Expert System
- Support Vector Machine
- Meta Learning Strategy
2.2. Credit Card Fraud Detection Data Mining Techniques
According to Wheeler, R and Aitken, S. (2000), the credit card fraud detection techniques are classified in two general categories: fraud analysis (misuse detection) and user behavior analysis (anomaly detection).
The first group of techniques deals with supervised classification task in transaction level. In these methods, transactions are labeled as fraudulent or normal based on previous historical data. This dataset is then used to create classification models which can predict the state (normal or fraud) of new records. There are numerous model creation methods for a typical two class classification task such as: rule induction, decision trees and neural networks. This approach is proven to reliably detect most fraud tricks which have been observed before, it also known as misuse detection.
The second approach (anomaly detection), deals with unsupervised methodologies which are based on account behavior. In this method a transaction is detected fraudulent if it is in contrast with user’s normal behavior. This is because we don’t expect fraudsters behave the same as the account owner or be aware of the behavior model of the owner. To this aim, we need to extract the legitimate user behavioral model (i.e. user profile) for each account and then detect fraudulent activities according to it. Comparing new behaviors with this model, different enough activities are distinguished as frauds. The profiles may contain the activity information of the account; such as transaction types, amount, location and time of transactions, this method is also known as anomaly detection, (Yeung, D., and Ding, Y., (2002).
It is important to highlight the key differences between user behavior analysis and fraud analysis approaches. The fraud analysis method can detect known fraud tricks, with a low false positive rate (FPR). These systems extract the signature and model of fraud tricks presented in dataset and can then easily determine exactly which frauds, the system is currently experiencing. If the test data does not contain any fraud signatures, no alarm is raised. Thus, the false positive rate (FRP) can be reduced extremely. However, since learning of a fraud analysis system (i.e. classifier) is based on limited and specific fraud records, it cannot distinguish or detect original frauds. As a result, the false negatives rate (FNR), may be extremely high depending on how ingenious the fraudsters are. User behavior analysis, on the other hand, greatly addresses the problem of detecting novel frauds. These methods do not search for specific fraud patterns, but rather compare incoming activities with the constructed model of legitimate user behavior. Any activity that is enough different from the model will be considered as a possible fraud.
Though, user behavior analysis approaches are powerful in detecting innovative frauds, they really suffer from high rates of false alarm. Moreover, if a fraud occurs during the training phase, this fraudulent behavior will be entered in baseline mode and is assumed to be normal in further analysis. (Yeung, D., and Ding, Y., (2002).

Now I will discuss briefly and introduce some current fraud detection techniques which are applied to credit card fraud detection tasks, also main advantage and disadvantage of each approach will be discussed.
2.2.1. Artificial Neural Network
An artificial neural network (ANN) is a set of interconnected nodes designed to imitate the functioning of the human brain, Douglas, L., and Ghosh, S., (1994). Each node has a weighted connection to several other nodes in adjacent layers. Individual nodes take the input received from connected nodes and use the weights together with a simple function to compute output values. Neural networks come in many shapes and architectures. The Neural network architecture, including the number of hidden layers, the number of nodes within a specific hidden layer and their connectivity, most be specified by user based on the complexity of the problem. ANNs can be configured by supervised, unsupervised or hybrid learning methods.
2.2.2. Supervised techniques
In supervised learning, samples of both fraudulent and non-fraudulent records, associated with their labels are used to create models. These techniques are often used in fraud analysis approach. One of the most popular supervised neural networks is back propagation network (BPN). It minimizes the objective function using a multi-stage dynamic optimization method that is a generalization of the delta rule. The back propagation method is often useful for feed-forward network with no feedback. The BPN algorithm is usually time-consuming and parameters like the number of hidden neurons and learning rate of delta rules require extensive tuning and training to achieve the best performance. In the domain of fraud detection, supervised neural networks like back-propagation are known as efficient tool that have numerous applications.
Ragh avendra Patidar, et al. used a dataset to train three layers back propagation neural network in combination with genetic algorithms (GA) for credit card fraud detection. In this work, genetic algorithms was responsible for making decision about the network architecture, dealing with the network topology, number of hidden layers and number of nodes in each layer.
Also, Aleskerov et al. developed a neural network-based data mining system for credit card fraud detection. The proposed system (CARDWATCH) had three layers auto associative architectures. They used a set of synthesized data for training and testing the system. The reported results show very successful fraud detection rates.
In a P-RCE neural network was applied for credit card fraud detection. P-RCE is a type of radial- basis function networks that usually applied for pattern recognition tasks. Krenker et al. proposed a model for real time fraud detection based on bi-directional neural networks. They used a data set of cell phone transactions provided by a credit card company. It was claimed that the system outperforms the rule based algorithms in terms of false positive rate.
Again in a parallel granular neural network (GNN) is proposed to speed up data mining and knowledge discovery process for credit card fraud detection. GNN is a kind of fuzzy neural network based on knowledge discovery (FNNKD).The underlying dataset was extracted from SQL server database containing sample Visa Card transactions and then preprocessed for applying in fraud detection. They obtained less average training errors in the presence of larger training dataset.
2.2.3. Unsupervised techniques
According to Yamanishi, K., and Takeuchi, J. (2004), the unsupervised techniques do not need the previous knowledge of fraudulent and normal records. These methods raise alarm for those transactions that are most dissimilar from the normal ones. These techniques are often used in user behavior approach. ANNs can produce acceptable result for enough large transaction dataset. They need a long training dataset. Self-organizing map (SOM) is one of the most popular unsupervised neural networks learning which was introduced by SOM and provides a clustering method, which is appropriate for constructing and analyzing customer profiles, in credit card fraud detection, as suggested. SOM operates in two phase: training and mapping. In the former phase, the map is built and weights of the neurons are updated iteratively, based on input samples, in latter, test data is classified automatically into normal and fraudulent classes through the procedure of mapping. After training the SOM, new unseen transactions are compared to normal and fraud clusters, if it is similar to all normal records, it is classified as normal. New fraud transactions are also detected similarly.
One of the advantages of using unsupervised neural networks over similar techniques is that these methods can learn from data stream. The more data passed to a SOM model, the more adaptation and improvement on result is obtained. More specifically, the SOM adapts its model as time passes. Therefore, it can be used and updated electronic in banks or other financial corporations. As a result, the fraudulent use of a card can be detected fast and effectively. However, neural networks have some drawbacks and difficulties which are mainly related to specifying suitable architecture in one hand and excessive training required for reaching to best performance in other hand. Williams, G. and Milne, P., (2004)
2.2.4. Hybrid supervised and unsupervised techniques
In addition to supervised and unsupervised learning models of neural networks, some researchers have applied hybrid models. John ZhongLei et.Al., proposed hybrid supervised (SICLN) and unsupervised (ICLN) learning network for credit card fraud detection. They improved the reward only rule of SICLN model to ICLN in order to update weights according to both reward and penalty. This improvement appeared in terms of increasing stability and reducing the training time. Moreover, the number of final clusters of the ICLN is independent from the number of initial network neurons. As a result the inoperable neurons can be omitted from the clusters by applying the penalty rule. The results indicated that both the ICLN and the SICLN have high performance, but the SICLN outperforms well-known unsupervised clustering algorithms. (R. Huang, H. Tawfik, A. Nagar., 2010)
2.2.5. Decision Trees and Support Vector Machines
Classification models which are based on decision trees and support vector machines (SVM) are developed and applied on credit card fraud detection problem. In this technique, each account is tracked separately by using suitable descriptors, and the transactions are attempted to be identified and indicated as normal or legitimate. Sahin, Y., and Duman, E.,(2011).
The identification is based on the suspicion score produced by the developed classifier model. When a new transaction is proceeding, the classifier can predict whether the transaction is normal or fraud.
In this approach, firstly, all the collected data is pre-processed before we start the modeling phase. Since, the distribution of data with respect to the classes is highly imbalanced, so stratified sampling is used to under sample the normal records so that the models have chance to learn the characteristics of both the normal and the fraudulent record’s profile. To do this, the variables that are most successful in differentiating the legitimate and the fraudulent transactions are founded. Then, these variables are used to form stratified samples of the legitimate records.
Later on, these stratified samples of the legitimate records are combined with the fraudulent ones to form three samples with different fraudulent to normal record ratios. The first sample set has a ratio of one fraudulent record to one normal record; the second one has a ratio of one fraudulent record to four normal ones; and the last one has the ratio of one fraudulent to nine normal ones.
The variables which are used make the difference in the fraud detection systems. Our main motive in defining the variables that are used to form the data-mart is to differentiate the profile of the fraudulent card user from the profile of legitimate card user. The results show that the classifiers of SVM and other decision tree approaches outperform SVM in solving the problem under investigation. However, as the size of the training data sets become larger, the accuracy performance of SVM based models becomes equivalent to decision tree based models, but the number of frauds caught by SVM models are still less than the number of frauds caught by decision tree methods. (Carlos Leon, Juan I. Guerrero, Jesus Biscarri., 2012)
2.2.6. Fuzzy Logic Based Systems
The purpose of Fuzzy neural networks is to process the large volume of information which is not certain and is extensively applied in our lives. Syeda et al in 2002 proposed fuzzy neural networks which run on parallel machines to speed up the rule production for credit card fraud detection which was customer-specific. His work can be associated to Data mining and Knowledge Discovery in data bases (KD). In this technique, he used GNN (Granular Neural Network) method that uses fuzzy neural network which is based on knowledge discovery (FNNKD), to train the network fast and how fast a number of customers can be processed for fraud detection in parallel. A transaction table is there which includes various fields like the transaction amounts, statement date, posting date, time between transactions, transaction code, day, transaction description, and etc. But for implementation of this credit card fraud detection method, only the significant fields from the database are extracted into a simple text file by applying suitable SQL queries. In this detection method the transaction amounts for any customer is the key input data. This preprocessing of data had helped in decreasing the data size and processing, which speeds up the training and makes the patterns briefer. In the process of fuzzy neural network, data is classified into three categories:
- First for training,
- Second for prediction, and
- Third one is for fraud detection.
The detection system routine for any customer is as follows: Preprocess the data from a SQL server database Extract the preprocessed data into a text file.
Normalize the data and distribute it into 3 categories (training, prediction, detection)
For normalization of data by a factor, the GNN has accepted inputs in the range of 0 to 1, but the transaction amount was any number greater than or equal to zero because for a customer only the maximum transaction amount is considered in the entire work. In this detection method, there are two important parameters that are used during the training that are:
- Training error and
- Training cycles.
With increase in the training cycles, the training error will be decreased. The accuracy of the results depends on these parameters. In prediction stage, the maximum absolute prediction error is calculated. In fraud detection stage also, the absolute detection error is calculated and then if the absolute detection error is greater than zero then it is checked to see if this absolute detection error is greater than the maximum absolute prediction error or not. If it is found to be true, then it indicates that the transaction is fraudulent otherwise transaction is reported to be safe. Both training cycles and data partitioning are extremely important for better results. The more there is data for training the neural network the better prediction it gives. The lower training error makes prediction and the detection more accurate. The higher the fraud detection error is, the greater is the possibility of the transaction to be fraudulent. (Peter J. Bentley, 2000)
3. Fraud Detection Methodology Description
This technique will follow the tabular procedure below for Electronic Banking transactions to demonstrate the fraud detection process. This process will consist of the following steps, the table below summarizes the steps:
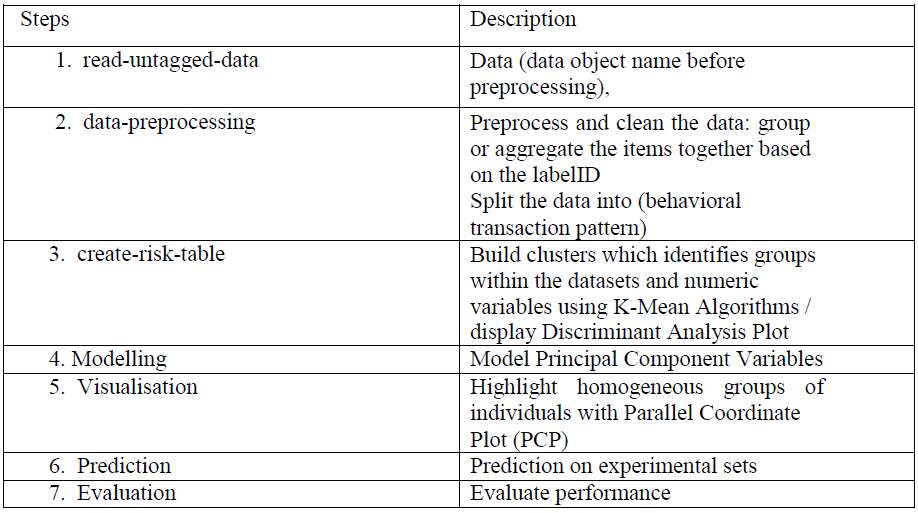
4. Data Pre-Processing for Fraud Detection
The deployment of unsupervised K-Mean clustering algorithm could be too demanding and unrealistic based on the mathematical and algorithms steps and procedures suggested in the various literature reviews and research work even for an expert user. Consequently, I source for a graphical user Interface package, such as rattle for easy manipulation and implementation based on the guide lines and suggestion by Williams, Graham.
Now, the problem at hand contains large number of data with no prior known features that can be used for classification. Clustering the data into different groups and trying to understand the behavior of each group is suggested as a methodology for modelling the user behavioral pattern of the transaction data sets. Thus, I explore the dtrans_data and Aggdtrans_data sets with R/Rattle to validate the legitimate user behavioral model. The algorithm chosen for clustering the transaction data is K-mean algorithm and the tools for the implementation are R and Rattle. The following sections will present the algorithm that will be used for clustering and the tools used for implementing the solution.
Data reduction techniques can be applied to obtain a reduced representation of the data set that is much smaller in volume, yet closely maintains the integrity of the original data.
5. K-Mean Cluster Algorithm
K-M EANS is the simplest algorithm used for clustering which is unsupervised clustering algorithm. This algorithm partitions the data set into k clusters using the cluster mean value so that the resulting clusters intra cluster similarity is high and inter cluster similarity is low. K-Means is iterative in nature it follows the following steps:
- Arbitrarily generate k points (cluster centers), k being the number of clusters desired.
- Calculate the distance between each of the data points to each of the centers and assign each point to the closest center.
- Calculate the new cluster center by calculating the mean value of all data points in the respective cluster.
- With the new centers, repeat step 2. If the assignment of cluster for the data points changes, repeat step 3 else stop the process.
- The distance between the data points is calculated using Euclidean distance as follows. The Euclidean distance between two points or features,
X1= (x11, x12… x1m) , X2= (x21, x22 ,. .. , x2m)
Advantages
- Fast, robust and easier to understand.
- Relatively efficient: O (t k n d), where n is objects, k is clusters, d is dimension of each object, and t is iterations. Normally k, t, d < n.
- Gives best result when data set are distinct or well separated from each other.
Disadvantages
- The learning algorithm requires apriori specification of the number of clusters centres.
- The learning algorithm provides the local optima of the squared error function.
- Applicable only when mean is defined i.e. fails for categorical data.
- Unable to handle noisy data and outliers
6. Summary of Findings
The main objective of this study was to find out the best solution (singular or integrated detection methodology) of controlling fraud, since it seems to be a critical problem in many organizations including the government.
Specifically, the following are the summary of my findings:
The fraud detection techniques as proffer by the research work are as followed:
- Pre-process original data set to suit techniques requirement
- Transform processed data variable fields, for detection techniques
- Applying K-Mean Cluster Analysis on the dtrans_data: which identifies groups within a dataset
- Reduce multidimensional data to lower dimensions while retaining most of the information using PCA
- Any numeric variables with relatively large rotation values (negative or positive) in any of the first few components are generally variables that I may wish to include in the modelling
- Determine the number of components to retain: the Loading Plot below reveals the relationship between variables in the space of the first two components
- Expressed main component variables as a linear combination of the original variables
- Highlight homogeneous groups of individuals with Parallel Coordinate Plot (PCP).
- Perform advance Exploratory Interactive Data Exploration Analysis (IDEA)
- The major technique used in the final analysis is unsupervised Machine Learning and predictive modeling with major focus on Anomaly/Outlier Detection (OD).
7. Conclusion
This research deals with the procedure for computing the presence of outliers using various distance measures and as a general detection performance result, I can conclude that nearest-neighbor based algorithms perform better in most cases when compared to clustering algorithms for a small data set. Also, the stability concerning a not-perfect choice of k is much higher for the nearest-neighbor based methods. The reason for the higher variance in clustering-based algorithms is very likely due to the non-deterministic nature of the underlying k-means clustering algorithm.
Despite of this disadvantage, clustering-based algorithms have a lower computation time. As a conclusion, I reckon to prefer nearest-neighbor based algorithms if computation time is not an issue. If a faster computation is required for large datasets, for example, just like the unlabeled dataset used for this research work or better still, in a near real-time setting, clustering-based anomaly detection is the method of choice, I observed.
Besides supporting the unsupervised anomaly detection research community, I also believe that the study and its implementation are useful for researchers from neighboring fields.
On completion of the underlying system I can conclude that the integrated technique system is providing far better system performance efficiency than a singular system using k-means for outlier detection. Since the main focus is on finding fraudulent data in a transaction dataset of credit cards, hence efficiency is measured on the basis of frequency of detecting outliers or unusual behavioral user pattern. For this purpose, the techniques have a mechanism consisting of clustering-based K-Nearest neighbor algorithm with Anomaly Detection Efficiency. Thus, we are having a system which is efficiently detecting unusual behavioral pattern as a final product.
References:
-
“CARDWATCH: A Neural Network-Based Database Mining System for Credit Card Fraud Detection”, Retrieved from https://ieeexplore.ieee.org/document/618940
“Analysis of electronic banking” Retrieved fromhttps://www.emerald.com/insight/content/doi/10.1108/02652320610701717/full/html -
Credit Card Fraud Detection with a Neural Network Retrieved from
https://www.semanticscholar.org/paper/Credit-card-fraud-detection-with-a-neural-network-Ghosh-Reilly/ba70a74262adec9dcfa47b5710752d2537a07af4 - Credit Card Fraud Detection Using Meta-Learning Retrieved from https://pdfs.semanticscholar.org/29b3/e330e0045e5da71cc1d333bed24b7a4670f8.pdf
-
Detecting Credit Card Fraud by Decision Trees and Support Vector Machines Retrieved from
http://www.iaeng.org/publication/IMECS2011/IMECS2011_pp442-447.pdf - Data Mining Techniques in Fraud Detection Retrieved from https://commons.erau.edu/jdfsl/vol3/iss2/3/
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal