Big Data as an e-Health Service
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 2080 words | ✅ Published: 18 Apr 2018 |
Abstract:
Bigdata in healthcare relates to electronic health records, patients reported outcomes all other data sets.It is not possible to maintain large and complex data with traditional database tools. After many innovation researches done by researchers Big Data is regenerating the health care, business data and finally society as e-Health .The study on bigdata e-health service. In this paper we come to know why the current technologies like STORM, hadoop, MapReduce can’t be applied directly to electronic-health services. It describes the added capabilities required to make the electronic-health services to become more practical. Next this paper provides report on architecture of bigdata e-health services that provides meaning of e-services, management operations and compliance.
Keywords: Introduction to big data, different types of technologies of bigdata, advantages of bigdata, applications of big data, solutions of e-health services, big data as a service provider, e-health data operation management.
Introduction:
What is bigdata?
Bigdata consisting of extremely huge amount of data sets which consists all kinds of data and it is difficult to extract. It can be described by the characteristics like variety, velocity, volume and variability.
- Variety
– It consists of data like structured, unstructured and semi structured data
– Structured data consists of databases, small scale health personal records, insurances, data wares, Enterprise Systems(like CRM, ERP etc)
– Unstructured data consists of analog data, Audio/video streams. Treatment data, research data
– Semi Structured data consists of XML, E-Mail, EDI.
- Velocity
– Velocity depends on time Sensitivity
– It also depends on streaming
- Volume
– It may consists of large quantities of files or small files in quantity
– for example , now a days single person can have more than one Gmail account. When he wants to login into a gmail accounts the system generates log files .
If a person login into gmail account multiple times through his different accounts then , the system generates huge number of log files that is stored in a servers using bigdata.
- Variability
– It shows the inconsistency of data depends on variation of time period .It may be a problem for analyzing the data.
Historically Bigdata in health care industries generate huge amount of electronic health datasets are so complex and difficult to manage by using the traditional software’s or hardware nor by using some database management tools. Now the current trend is to make these huge amount of data as Digitalization so that this whole digital healthcare system will transform the whole healthcare process will become more efficient and highly expensive cost will be reduced. In other words Bigdata in healthcare is evolving into a propitious field for providing perception from large set of data and it produces outcomes which reduces the cost.
Bigdata in healthcare industry is stunning not only because of huge volume of datasets like clinical records of patients health reports, patient insurance report, pharmacy, prescriptions , medical imaging , patient data in electronic patient records etc but also multiplicity of data types and the speed of increasing the records.
Some of the reports generated by researchers on the health care systems shows that, one of the health care system alone has reached in 2011, 150 Exabyte. At this rate of increase of growth, in future the bigdata reaches Zettabyte scale and soon it reaches to Yottabyte from various sources like electronic medical records Systems, social media reports, Personal health reports, mobile health care records, analytical reports on large array of biomedical sensors and smart phones.
The electronic-health medical reports generated by single patient generates thousands of medical reports which includes medical reports, lab reports, insurances, digital image reports , billing details etc.All these records are needed to be stored in database for validating , integrating these records for meaningful analysis. If these reports are generated by multiple patients across the whole world of healthcare processing system then we have to combine these whole data into a single system which is a big challenge for Big Data.
As the volume and Source of storing the data increases rapidly then we can utilize the e-health data to reduce the cost and improves the treatment. We can achieve it by investigating the big data e-health System that satisfies Big Data applications.

BIG DATA FOUNDATIONS FOR E-HEALTH :
The Following Figure 1 shows the bigdata service environment architecture that provides the support for electronic-health applications from different sources like testing center, individual patients, insurance facilitator and government agencies .All these produces some standard health records are connected commonly to a national healthcare network.
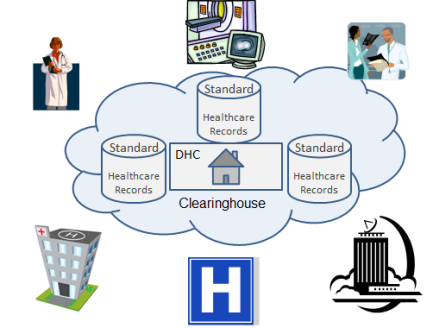
Figure 1. e-Health Big Data Service Environments
Different types of Data sources :
The different types of data sources may include structured database, unstructured datasets and semi structured information
- Some of the standard structured data that deals with the drug insurance policy by NCPDP (National Council for Prescription Drug Program) and NCPDP SCRIPT for messaging the electronic prescription for validating the interaction between drug to drug, medical database records, dosage of drug, maintain the records.
- The semi structured data related to radiology pictures are changed over the IP networks is provided by DICOM(Digital Imaging and communication in Medicine).
- The e-Health system store, gather the medical information, patient information to the doctors unexpectedly includes medical information, vaccination details, diagnostics’ reports.
- HDWA Healthcare Data Warehousing Association it provides the environment for from others. They work collaboratively which helps them to deliver accurate results or solutions from their own organizations
- A strong relationship and interaction from test facilitators and technical team is maintained within the organization.
- We have to face the challenges for utilizing the unstructured data related to different concepts, sharing and accessing the data.
Big data solutions and products:
Bigdata investigation requires knowledge about storing, inspecting, discovering, visualizing the data and providing security by making some changes to some of technologies like Hadoop, MapReduce, STORM and with combinations.
STROM:
STROM is a distributed, open source , real time and fault-tolerant computational system. It can process the large amount of data on different machines and in real time each message will be processed. Strom programs can be developed by using any programming languages but especially it uses java , python and other.
Strom is extremely fast and has the capability to process millions of records per second per node as it is required for e-health services. It combines with the message queuing and database technologies. From the figure 2 we can observe that a Strom topology takes huge amount of data and process the data in a typical manner and repartitioning the streams of data between each stage of process.
A strom topology consists of spout and bolts that can process huge amount of data. In terms of strom components the spout reads the incoming data and it can also read the data from existing files .if the file is modified then spout also enters the modified data also. Bolt is responsible for all processing what happens on the topology , it can do anything from filtering to joins, aggregations, talking to database. Bolts receive the data from spout for processing.

Figure 2. Illustration of STORM Architecture
(ref: https://storm.apache.org/)
Some of the important characteristics of Strom for data processing are:
- Fast-It can process one million 100 bytes per second per node
- Scalable-with parallel calculations that runs across the machine
- Fault-tolerant-if a node dies strom will automatically restart them
- Reliable-strom can process each unit of data alleast once or exactly once
- Easy to operate-once deployed strom can be operated easily
(ref: http://hortonworks.com/hadoop/storm/)
Hadoop for batch processing:
Hadoop was initially designed for batch processing i.e., it takes inputs as a large set of data at once, process it and write the output. Through this batch processing and HDFS(hadoop distributed file system) it produce high throughput data processing.Hadoop is another framework , runs on MapReduce technology to do distributed computations on different servers.
(ref diagram: http://en.wikipedia.org/wiki/Apache_Hadoop)
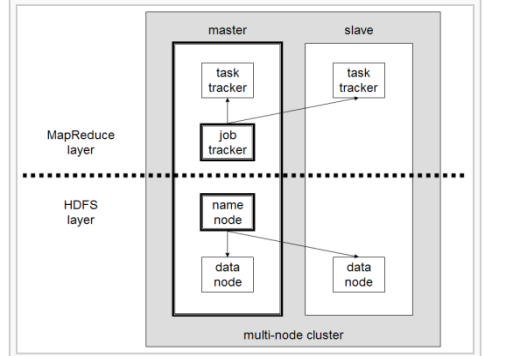
Figure 3. Hadoop Processing Systems
From the figure 3 we can observe that a hadoop multi-node cluster , it consists of single master node and slave node. A master node has different trackers like task tracker for scheduling the tasks , job tracker server handles with the job appointments in a order. Master also acts like a data node and name node. The slave node acts like a task tracker and data node which process the data only by slave-node only. HDFS layer deals with large cluster of nodes manage the name node server which prevents the corruption of file by taking the snapshots of the name node memory structure.
Many top companies uses the hadoop technology plays a prominent role in the market.The Vendors who uses Hadoop technology will produce accurate results with high performance, scalability in output and cost is reduced. Some of the companies like Amazon, IBM, Zettaset, Dell and other uses Hadoop technology for easy analysis, provides security, user friendly solutions for complex problems.( http://www.technavio.com/blog/top-14-hadoop-technology-companies)
MAPREDUCE:
In 2004, Google released a framework called Hadoop MapReduce. This framework is used for writing the applications which process huge amount of multi-terabyte data sets in parallel on large number of nodes. MapReduce divides the work loads into multiple tasks that can be executed parallel. Computational process can be done on both file system and database.
(ref: http://en.wikipedia.org/wiki/MapReduce)
MapReduce code is usuallay written in java program and it can also can write in another programming languages. It consists of two fundamental components like Map and Reduce. The input and output generated by MapReduce is in the form of key and value pair. The map node will take the input in the form of large clusters and divides it into smaller clusters were the execution process is easy. Rather Mapreduce provides support for hadoop distributed file system can store the data in different servers. This framework provides support for thousands of computational applications and peg bytes of data.
Some of the important features of mapreduce are scale-out architecture , security and authentication, resource manager, optimized scheduling, flexibility and high availability.
Additional tools are needed to add and should be trained for e-Health files to reduce the complexity because some of the compressed files like electronic-health DICOM picture file should be mapped to a singler Map Reducer so it reduces the BigdData effectiveness. The Hadoop big data applications has imposed a limitations on big data technologies has focused on the applications like offline informatics systems.
4) Programming Tools:
The other solution for the e-Health bigdata is MUMPS, it is an programming tool. MUMPS is abbreviated as Massachusetts General Hospital Utility Multi-Programming System. It is also known as M programming language. M is a multi user and it is designed to control the huge amount of database. M programming can produce high performance in health cares and in financial applications.
M provides simple data considerations in which the data is given in the form of string of characters and the given data is structured in a multidimensional array. M requires support for sparse data.Accorrding to the research done by the scientist in US hospitals they are maintaing the electronic Health records (HER) using M language including Vista(Veterans Health Information Systems and Technology Architecture) which manages all hospitals care facilities run by the Department of Veterans.
(ref: http://opensource.com/health/12/2/join-m-revolution)
In future some of the analytical algorithms are developed to solve the problems faced with the big data applications
Additional e-Health (Big Data) Capabilities:
The additional capabilities provided by the Big data e-Health services are Data Federation and aggregation, Security and Regulatory Concerns and Data Operational Management. The bigdata provides the services which helps to organize and store the huge amount of data. Those data is is digitalization , consists of large amount of datasets consists information related to patients all reports.
1) Data Federation and Aggregation:
Data Federation is a type of software which collections the data from the multiple users and integrates the data.Typically traditional software cannot given the solution to store the huge amount of data in hardwares or by some database management tools.But the Data federation will provide a solution based upon the bigdata architecture is based by collecting the data inside and outside of the enterprise through the layer.
Some of the important data federation tools are Sysbase federation, IBM InfoSphere Federation server and so on.
(ref: http://etl-tools.info/en/data-federation.html)
2) Security and Regularity Concerns:
Security is one of the important requirement to describe bidgata e-health services.Security plays a important role because patient share their personl information with the doctors which help the physician to give the correct treatment
3) Data Operational Management
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal